Parameters/Knobs
Detailed description of parameters/knobs for BCn compression/encoding and RDO
using KTX CLI tools (i.e., ktx create, ktx encode). The output of the usual
help command (ktx encode --help) may not be sufficient to explain the details
of what each parameter does.
There are also a couple of advices here and there that should be taken with a grain of salt since I only tested some parameters with very few samples.
--bc7-quality
The quality level configures the quality-performance tradeoff for BC7 encoder. Default is ‘medium’. The quality level can be set between fastest and exhaustive via the following fixed quality presets where each preset is an OR’ed set of flags:
+ ---------- + ---------------------------- +
| Level | OR'ed flags |
| ---------- | ---------------------------- |
| fastest | (equivalent to flags = 128) |
| faster | (equivalent to flags = 176) |
| fast | (equivalent to flags = 179) |
| medium | (equivalent to flags = 255) |
| thorough | (equivalent to flags = 1023) |
| exhaustive | (equivalent to flags = 3967) |
+ ---------- + ---------------------------- +






Since I don’t care about encoding speed, I usually set it to exhaustive
(this does not affect the speed of the BC7 decoder whatsoever).
--bc1-quality
I haven’t used BC1/BC3 at all, so I will just copy the help text for this argument here (just read the note below as to why BC7 is most probably a better choice for you):
Note on BC1 vs. BC3 vs. BC7: apart from lower VRAM consumption (4bpp vs. 8bpp) and better GPU texture cache efficiency, there’s little need to use BC1 now. BC3 still has an advantage vs. BC7, because it very strongly separates how RGB is encoded from the alpha channel, in a predictable way.
The quality level configures the quality-performance tradeoff for BC1 and, subsequently, BC3 encoders. The quality level can be set in the range [0, 19] with (0) being the ‘fastest’ and (19) the slowest but most ‘exhaustive’. Default is (15) ‘thorough’. Can also be set via the following aliases:
+ ---------- + ---------------------------- +
| Level | Quality |
| ---------- | ---------------------------- |
| fastest | (equivalent to quality = 0) |
| fast | (equivalent to quality = 5) |
| medium | (equivalent to quality = 10) |
| thorough | (equivalent to quality = 15) |
| exhaustive | (equivalent to quality = 19) |
+ ---------- + ---------------------------- +
--rdo
Ideally, you don’t want to directly save BC7-compressed KTX textures on the disk because BC7 is simply not designed to reduce size on storage mediums (or to reduce bit rate for the target transmission medium). What you probably want to do is to apply another compression on top of the BC7-compressed texture to, potentially, significantly reduce its size while adding little overhead for a further decompression step on the CPU (which is very fast). For KTX this is usually some lossless, Deflate-based compression like ZStandard or Zlib.
Some noteworthy notes:
- RDO is a lossy post-processing method.
- RDO has no affect whatsoever on the decoding speed of the underlying BC7-compressed texture (Or any other method for that mater. GPU BCn decompression speed is constant and unaffected by any BCn encoding parameters).
- It makes no sense to apply RDO for textures that will not be supercompressed using Deflate-based algorithm (i.e., only apply RDO if you intend to deflate KTX2 BCn-compressed textures using ZStandard or Zlib).
- Usually results in significantly slower encoding times (I usually don’t care about encoding time so this is completely fine for me).
I always enable this since this consistently results in files 50% or more smaller.
This setting enables rate distortion optimization (RDO) post-processing step on BCn-encoded blocks to reduce entropy for Deflate-based compressors. This is primarily used to reduce size on disk when a further compression is applied (Zlib/ZSTD supercompressions). RDO parameters are only used if this is set. Setting this might result in significantly slower encoding time at the benefit of potentially significantly lower bit rate for Deflate-based compressors (i.e., number of bits per encoded texel).
For kodim23, if we apply RDO with lambda 0.5 and window size of 8192:


kodim23 BC7 compressed KTX2 size: 385KB
kodim23 BC7 compressed KTX2 size (ZSTD): 362KB
kodim23 BC7 compressed KTX2 size (RDO + ZSTD): 224KB
RDO achieved a reduction of ~40% relative to non-RDO ZSTD compressed KTX2 files.
For kodim01 (although it technically contains almost the same ratio of smooth blocks, they are significantly less noticeable than the ones in kodim23):
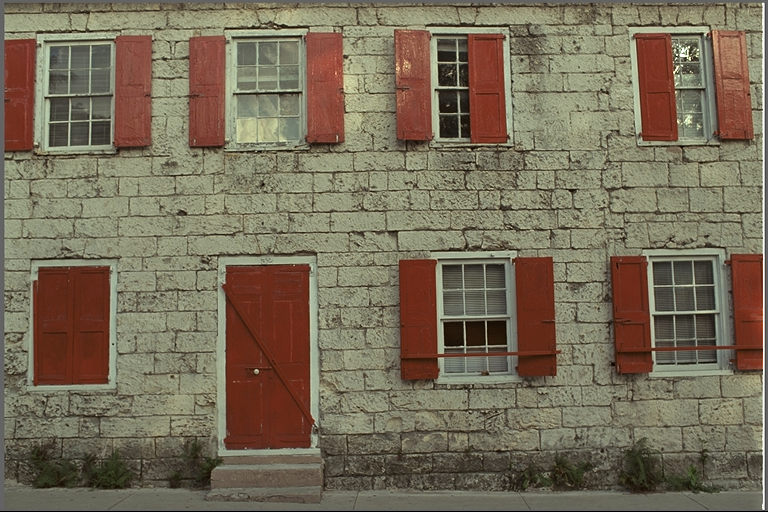
kodim01 BC7 compressed KTX2 size: 385KB
kodim01 BC7 compressed KTX2 size (ZSTD): 357KB
kodim01 BC7 compressed KTX2 size (RDO + ZSTD): 225KB
--rdo-lambda
RDO quality scalar (lambda). Controls rate vs. distortion tradeoff. Lower values yield higher quality/larger LZ compressed files, higher values yield lower quality/smaller LZ compressed files. A good range to try is [0.25,8]. Full range is [0.1,50.0]. Default is 0.5.
The post-processor tries to minimize:
distortion * smooth_block_scale + rate * lambda
(rate is approximate LZ bits and distortion is scaled MSE multiplied by the smooth block MSE weighting factor). Larger values push the post-processor towards optimizing more for lower rate, and smaller values more for distortion. 0=minimal distortion.
This is the most influential parameter/knob for RDO. You just have to play around with the values and figure out a good tradeoff (always measure resulting bit rate with the actual Deflate algorithm - e.g, ZSTD).
--rdo-window-loopback-size
The number of bytes the encoder can look back from each block to find matches. The larger this value, the slower the encoder but the higher the quality per LZ compressed bit. You don’t need a huge window to get large gains.
This parameter significantly influences the resulting bit rate at the expense of significantly longer encoding times.
If you don’t care about encoding speed, then set this to a high value (e.g., 8192). From limited testing, I found values > 8192 to take significantly much longer while offering very little bit rate improvements.
TODO: at some point I might add a bit-rate vs. window-size + a window-size vs. time graphs.
--rdo-max-smooth-block-std-dev
This controls if and to which degree blocks are considered smooth blocks. RDO
results in very noticeable artifacts for smooth blocks hence why MSE of these
blocks has to be adjusted (i.e., increased) by a factor. This factors
(smooth_block_mse_scale) is computed as follows:
float max_std_dev = compute_block_max_std_dev(/* ... */);
float yl = clampf(max_std_dev / rdo_max_smooth_block_std_dev, 0.0f, 1.0f);
yl *= yl;
float smooth_block_mse_scale = lerp(rdo_max_smooth_block_mse_scale, 1.0f, yl);
So essentially: if the std dev. of a block exceeds this value, then it won’t be
considered as a smooth block (i.e., the smooth block MSE scale factor will be
set to 1.0f for this block). The smaller the ratio of the standard deviation of
this block to this value the more the smooth block
MSE scale factor approaches --rdo-max-smooth-block-mse-scale.
Range is [.01,65536.0]. Larger values expand the range of blocks
considered smooth and consequently hurt bit rate. Lower values may result in
noticeable artifacts/distortion at the benefit of greater bit rate. Default is
18.0.
This is what you get without smooth block handling (i.e., setting this parameter as low as possible):’/home/walcht/KTX-Software/kodim01_rdo.png’


I usually just keep this at 18.0f and rarely play around with it unless I notice some artifacts around the edges as the ones seen above.
For why scaling the MSE of smooth blocks is so crucial in RDO, see [–rdo-max-smooth-block-mse-scale][#–rdo-max-smooth-block-mse-scale]
--rdo-max-smooth-block-mse-scale
While --rdo-max-smooth-block-std-dev controls if and to which degree blocks
should be considered smooth blocks, --rdo-max-smooth-block-mse-scale
controls the MSE scale factor for a given smooth block. The equation is as
follows:
float max_std_dev = compute_block_max_std_dev(/* ... */);
float yl = clampf(max_std_dev / rdo_max_smooth_block_std_dev, 0.0f, 1.0f);
yl *= yl;
float smooth_block_mse_scale = lerp(rdo_max_smooth_block_mse_scale, 1.0f, yl);
Setting this to 1.0f disables smooth block handling and will most probably result in significantly noticeable artifacts:


By default, this value is automatically computed based on the set
--rdo-lambda. I usually just let it be automatically computed, but you have
the option to supply a value (extra knob) and test it by yourself.
--rdo-no-ultrasmooth-blocks
See Geldreich’s original blog post about ultra-smooth block handling here.
Disables ultra-smooth blocks handling (think of gradients, skies, etc.).
Ultra-smooth block handling detects extremely smooth blocks and encode them with a significantly higher MSE scale factor (vs. other non-smooth or non-ultra-smooth blocks). When enabled, a per-block mask image is computed, filtered, then an array of per-block MSE scale factors is supplied to the ERT. The end result is much less significant artifacts on regions containing very smooth blocks (e.g., gradients). This does hurt rate-distortion performance. Default is false. This only applies to BC1, BC3, and BC7’s RGB blocks (alpha is ignored). For other formats, this is silently ignored.
A block is considered ultra-smooth if all the following conditions are met (some of these are quite confusing and complex, to keep it simple, just follow the images below: a black pixel is an ultra-smooth block):
- The mean of a block’s average Luma 709 is in [DARK_THRESHOLD, BRIGHT_THRESHOLD[ (i.e., its luminance is neither too dark nor too bright). These are set to 13 and 222 respectively. The reasoning behind this is that the human eye already doesn’t notice the difference at these extremes and thus doesn’t make sense to hurt the bit rate for lower distortion via ultra-smooth block handling for these blocks (even though, technically, they might be ultra-smooth).
- The max std dev. of a block (which is computed as std dev. of each RGB component then the maximun between them is picked) is strictly lower than ULTRASMOOTH_BLOCK_STD_DEV_THRESHOLD (which is set to 2.9)
- For each block:
yl = max_std_dev/ULTRASMOOTH_BLOCK_STD_DEV_THRESHOLD; yl *= yl; - The following filtering/spread out steps are performed:



The resulting artifcats you get after setting this (i.e., disabling ultra-smooth blocks handling) are significantly noticeable for images containing gradients. For an example, let’s pick the delorean.jpg image (JPEG because I couldn’t find the original PNG :-/):
Hereafter, whenever ZSTD or Zlib are mentioned, they are used with highest
compression level (--zstd 22 and --zlib 9).
-
Original (JPEG):

Delorean original image (3000 x 1480). Notice the very smooth background gradient. With the following stats:
total nbr smooth blocks (%): 94.6692 total nbr ultra smooth blocks (%): 69.8061 -
BC7 (no RDO):
Encoding without RDO results in the following bit rates:
bits/texel (ZLIB): 2.340 bits/texel (ZSTD): 1.996 -
BC7 + RDO + lambda 0.5 + 8192 window size (ultra-smooth blocks handling disabled vs. enabled):


On the left: Delorean BC7 + RDO. Bit rates: 1.305 bits/texel (ZLIB + RDO) and 1.251 bits/texel (ZSTD + RDO) Notice how the background gradient are very noticeably blocky. On the right: Delorean BC7 + RDO + ultra-smooth blocks handing. Notice how the background gradient are noticeably less blocky. See stats below for the increased bit rate: from 1.251 to 1.365 bits/texel (ZSTD + RDO). With the following stats:
+ -------------------------------- + ----------------- + -------------- + | parameter/stat | no RDO | RDO | | -------------------------------- | ----------------- | -------------- | | rdo-max-smooth-block-std-dev | 18.0 | 18.0 | | rdo-max-rms-ratio | 10 | 10 | | rdo smooth block max MSE scale | 19.375 | 19.375 | | rdo try two matches | 1 | 1 | | rdo allow relative movement | 0 | 0 | | rdo skip zero MSE blocks | 0 | 0 | | total nbr modified blocks (%) | 99.0137 | 99.0364 | | total second matches | 28799 | 32996 | | ktx encode + rdo runtime (s) | 68.022034052 | 73.945519788 | | bits/texel (ZLIB + RDO) | 1.305 | 1.440 | | bits/texel (ZSTD + RDO) | 1.251 | 1.365 | + -------------------------------- + ----------------- + -------------- +
You probably want to disable ultra-smooth block handling for images/textures that do not contain noticeable amount of visible smooth blocks (don’t just rely on the stats about smooth blocks since, as can be seen above, enabling ultra-smooth block handing for kodim01 results in no noticeable improvements while for kodim23 and delorean the improvements are very noticeable).